LLM エージェントが業務に組み込まれる時代に、上場企業データインフラはどう設計されるべきか。
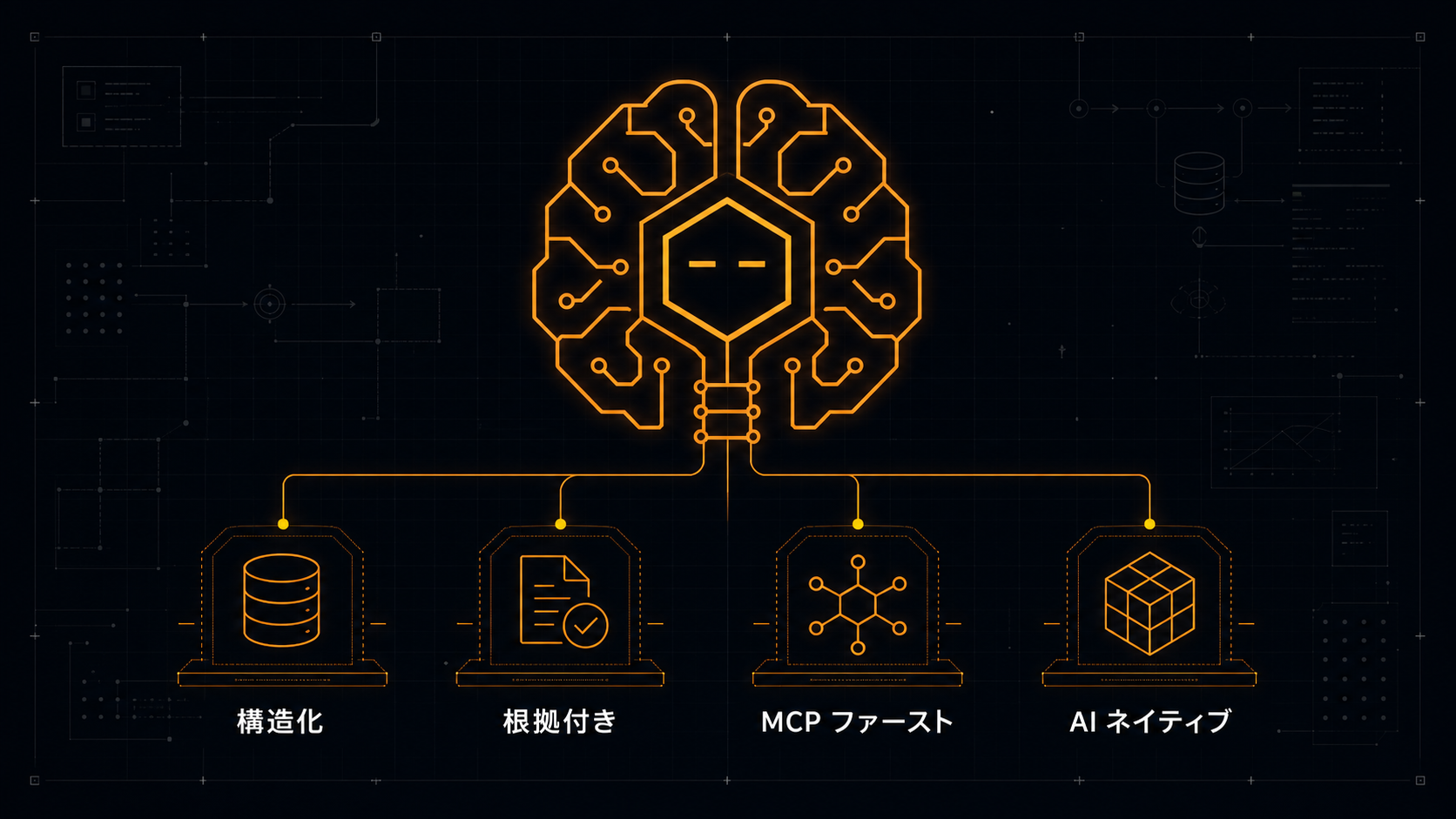
旧来の上場企業データベースは、人間がブラウザで開いて目で読む前提で作られていました。スクレイピングを許容する代わりに、信頼性は読み手側の判断に任せる設計です。LLM エージェントが直接データを呼ぶ時代には、この前提が成り立ちません。構造化・根拠付き・MCP ファーストの設計が、AI 時代のデータインフラの最低条件です。
EDINET DB は、金融庁 EDINET の XBRL を一次ソースとして扱い、抽出値と原典を分けて保持し、AI 推定値と確定値を分離する設計をとっています。これは「日本データインフラ」事業全体の設計思想の出発点でもあります。SEISAKU DB / FUDOSAN DB / BOUSAI DB も同じ思想で設計されており、AI エージェントから直接呼ばれる前提で構築されています。
詳細は EDINET DB ブログをご覧ください → LLM エージェント時代の上場企業データインフラ設計